
Data Point 04/17
China competition, OpenPhil insanity, huge Stanford AI report

Welcome to our inaugural issue! Data point is a brief weekly summary of the most important AI policy, industry, and research developments that will soon be on your radar.
My interview with Dean W. Ball from George Mason University / Mercatus on competition with China and existing AI regulation. He argues that the historical approach to strategic competition, incentivizing domestic production with a light hand, continues to be the optimal strategy on AI.
Policy
The Open Philantropy funded Center for AI Policy released draft legislation calling for, among other things, unilateral emergency powers to seize AI hardware and software, as well as to arrest developers. Meanwhile, OpenPhil ally Paul Christiano was appointed to the NIST AI Safety Institute.

Matt Mittlesteadt on the new OMB AI Guidlines
“At a high level, these new restrictions represent a potential catastrophe for public sector AI diffusion. By going all in on AI safety rules the administration is failing to consider budgetary and administrative realities and, as a result, is risking slamming the breaks on federal AI all together.”
Dean Ball on the comments to the NTIA on open source/open weight AI. After analyzing all 332 comments using Google Gemini, he found that “the results are clear: the comments overwhelmingly support maintaining access to open models”.
Industry
Udio, or “ChatGPT for Music” launched. Its $10 million raise represents interest in a rapidly diversifying AI market. It joins competitor Suno in the AI-generated music market.
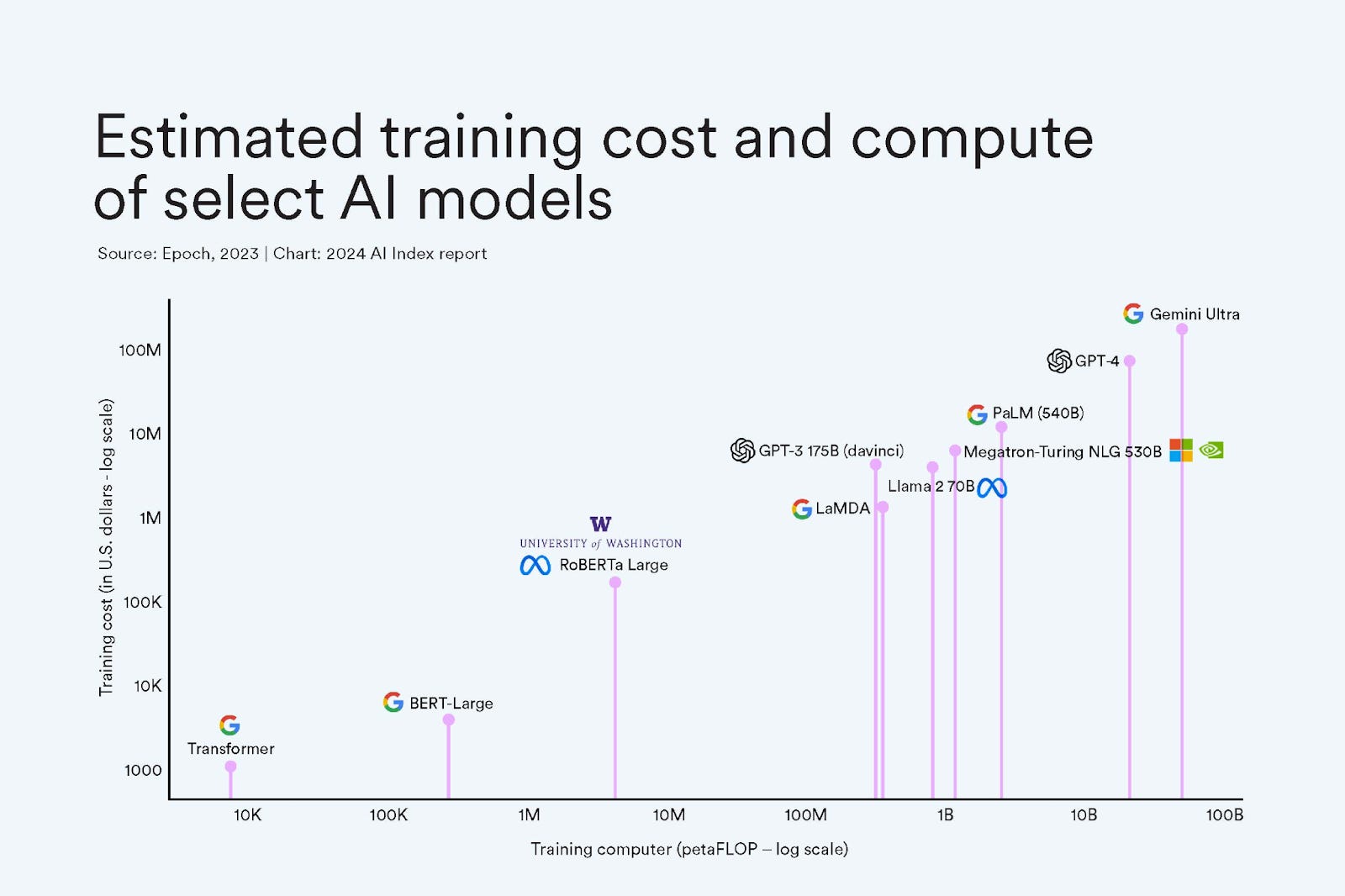
Stanford released a massive report on the leading players in the AI industry. Here are key charts on global competition, and competition between leading players. One example:
Research
An early paper on scaling laws, a key factor in predicting the growth of AI, has some newly identified weaknesses. Performance returns to investing in more AI hardware may be more uncertain than they seem.
Google researchers published results on a state space model structure. This is important because it enables longer context windows, in other words the ability for their language models to process much longer documents and user requests at a time.